Finanzprodukte wie beispielsweise Versicherungen berechnen Beiträge mit komplexen mathematischen Verfahren. Je nach Produkt fließen mehr oder weniger viele Einflussgrößen in die Berechnung ein, um unterschiedliche Risiken angemessen zu berücksichtigen. Wenn diese Berechnungsverfahren in Softwarelösungen implementiert werden, müssen die Algorithmen gegen die fachlichen Vorgaben getestet werden. Das stellt Softwareingenieure vor eine besondere Herausforderung, denn Berechnungsfunktionen verhalten sich häufig nicht überall stetig im mathematischen Sinne. Schon geringe Änderungen an den Eingabewerten können größere Änderungen an den Prämien hervorrufen.
Funktionen mit Sprüngen
Die Ursache liegt häufig im Modell der Produktentwicklung. Versicherungsprodukte werden von Aktuaren oft zunächst mit Excel entwickelt. In Excel ist es vergleichsweise einfach, das Verhalten von Parametern über Lookup-Tabellen zu definieren. Diese Lookups sind mathematisch betrachtet Stützstellen einer Funktion. Der Lookup in Excel entspricht dann häufig einer Treppenfunktion. Warum ist das wichtig? Als Softwaretester liegt es nahe, ein konsistentes Verhalten einer Anwendung zu erwarten. Wenn ich das Verhalten der Anwendung an den Extremwerten und in der Mitte teste, könnte ich erwarten, dass sie sich auch an den Zwischenwerten entsprechend gutartig verhält. Genau das ist bei einem stützstellenbasierten Ansatz mit Excel-Lookup-Algorithmen aber nicht zwingend der Fall. Zusätzlich wird es komplexer, wenn solche Variablen im Excel-Algorithmus mit Bedingungen verknüpft werden, wie zum Beispiel:
Wenn Tarifgruppe > 100 und Schadenquote > 1 dann Tarifgruppe -= 10Mit Tests nach Gefühl kommt man hier nicht weiter. Das macht man ja sowieso nie — oder man nennt es exploratives Testen. Ohne Kenntnis des tatsächlichen Algorithmus lassen sich die neuralgischen Parameterkombinationen, bei denen die Berechnungsfunktion ihr Verhalten ändert, nicht zuverlässig vorhersagen. Die Testabdeckung muss entsprechend hoch angesetzt werden. Testen ist allerdings teuer. Besonders bei Ende-zu-Ende-Tests ist die Durchführungsdauer hoch. Eine Automatisierung der Testdurchführung kann zwar den Personaleinsatz beim Testen reduzieren, erhöht aber die Last auf dem System. Auch das verursacht Kosten. Da das Testen in einen Projektrahmen eingebettet ist, führt eine längere Testdauer außerdem zu einer verlängerten Projektdauer und damit zu Zusatzkosten durch die längere Bereithaltung des Projektteams. Während sich die Werte einer einzelnen Variablen noch vergleichsweise gut bestimmen lassen, zum Beispiel durch Extraktion der Wertetabellen aus den Lookups, ist das Zusammenspiel mehrerer Variablen deutlich schwieriger zu überschauen. Eine Analyse des Referenzrechners in Bezug auf abhängige Variablen ist mit KI zwar gut machbar, löst das Problem aber nicht vollständig. Denn im Soll-Ist-Vergleich zwischen Referenzsystem und dem zu testenden System bleibt das Testsystem eine Blackbox, die durch bewusste oder unbewusste Programmierentscheidungen ein anderes Verhalten aufweisen kann.
Paarweise unabhängige Kombinationen – PICT
Ein ökonomischer Weg, eine sinnvolle Testabdeckung in den Parameterkombinationen zu erreichen, ist das PICT-Verfahren. PICT steht für Pairwise Independent Combinatorial Testing. Der Begriff beschreibt den Ansatz recht genau: Ausgehend von den Testwerten der Einzelparameter sorgt das PICT-Verfahren dafür, dass für je zwei Parameter alle Wertekombinationen dieser beiden Parameter abgedeckt sind. Da ein Testdatensatz nicht nur die beiden jeweils betrachteten Parameter enthalten muss, sondern auch die übrigen Parameter, entstehen automatisch auch bestimmte 3er- und 4er-Kombinationen. PICT ersetzt damit nicht die fachliche Teststrategie. Es hilft aber, eine große Menge möglicher Eingabekombinationen systematisch auf eine kleinere, besser handhabbare Menge von Testfällen zu reduzieren.
Beispiel
Ein Beispiel soll das PICT-Verfahren verdeutlichen. Nehmen wir ein Versicherungsprodukt, beispielsweise eine Hausratversicherung, mit den prämienrelevanten Einflussgrößen Laufzeit, Wohnfläche, Schmuck und einem Bonusrabatt. Wir halten die Problemgröße bewusst klein, um die kombinatorische Entwicklung intuitiv einschätzen zu können. Für jeden dieser Parameter legen wir die zu testenden Werte fest.
Parameter und Werte des Beispiels
-
Laufzeit: 1, 3, 5 Jahre
-
Wohnfläche: 30 qm, 50 qm, 100 qm, 200 qm
-
Schmuck mitversichert im Wert von: 0 €, 100 €, 1.000 €
-
Bonusrabatt: ja, nein Rechnerisch ergeben sich 72 Kombinationen. Eine vollständige Abdeckung hätte also 72 Testdatensätze.
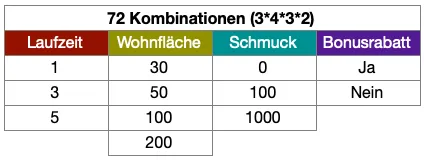
Parameterpaare und deren Kombinationen
Das PICT-Verfahren betrachtet nun alle Parameterpaare und sorgt dafür, dass in diesen Paaren jeweils alle Wertekombinationen abgedeckt sind. Laufzeit hat 3 Werte, Wohnfläche 4 Werte. Für die Kombination Laufzeit × Wohnfläche ergeben sich also 12 Kombinationen. Bricht man dies für alle Parameterpaare herunter, kommt man auf 53 Paar-Kombinationen. Das ist allerdings noch naiv gerechnet, weil die übrigen Parameter in realen Testdatensätzen bereits mitverteilt werden und dadurch mehrere Paar-Kombinationen gleichzeitig abgedeckt werden können.
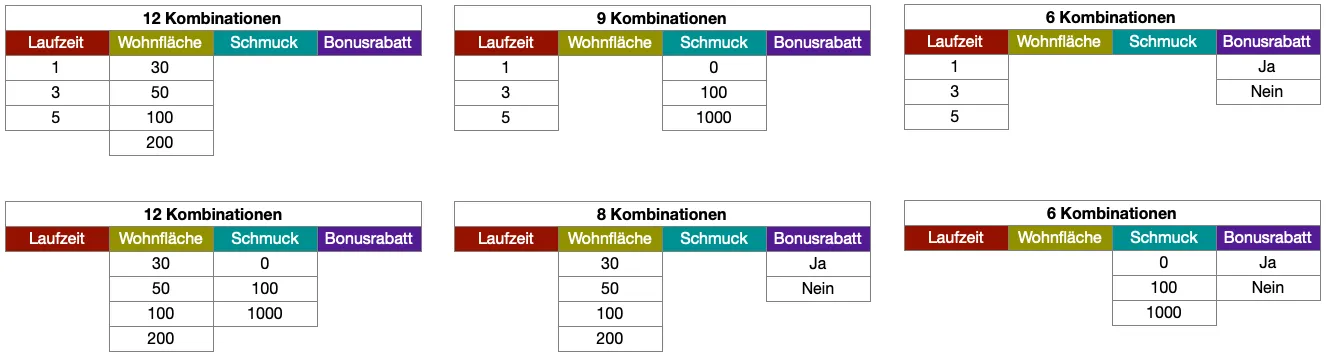
Datenpacking im PICT-Verfahren
Das PICT-Verfahren versucht nun, die Kombinationen in gemeinsame Testdatensätze zu packen. Das Ergebnis sind in diesem Beispiel 14 dicht gepackte Testdatensätze.
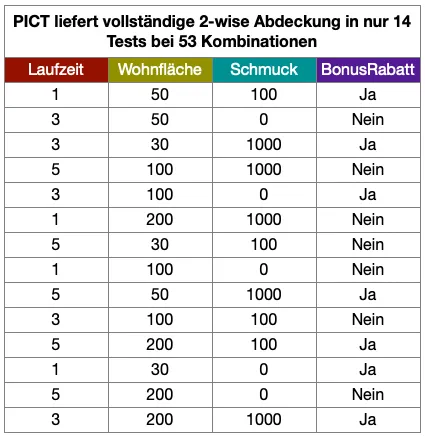
14 PICT-Testfälle bei 72 rechnerischen Kombinationen: In diesem kleinen Beispiel hat das noch keine große praktische Bedeutung. Interessant wird es, wenn wir mehr Werte oder mehr Parameter zulassen. Der Einfachheit halber nehmen wir an, dass alle Parameter genau 10 Werteausprägungen haben. Ein Testlauf des PICT-Verfahrens zeigt, dass die Zahl der PICT-Testdatensätze bei der weiteren Hinzunahme von Parametern nur moderat anwächst.
In der Praxis wächst die Zahl der Testfälle bei paarweiser Abdeckung meist deutlich langsamer als die vollständige kartesische Produktmenge. Das ist der entscheidende wirtschaftliche Vorteil des Verfahrens: Jeder zusätzliche Parameter erhöht den Testumfang, aber nicht in dem Maße, wie es bei einer vollständigen Kombination aller Werte der Fall wäre.
Die grüne Linie in der folgenden Grafik zeigt die Summe aller 2-er Kombinationen. die blaue Linie zeigt die Anzahl der pairwise Kombinationen, die rote Linie die Anzahl der 3-wise.
Auf der horizontalen Achse ist die Anzahl der Parameter eingetragen.
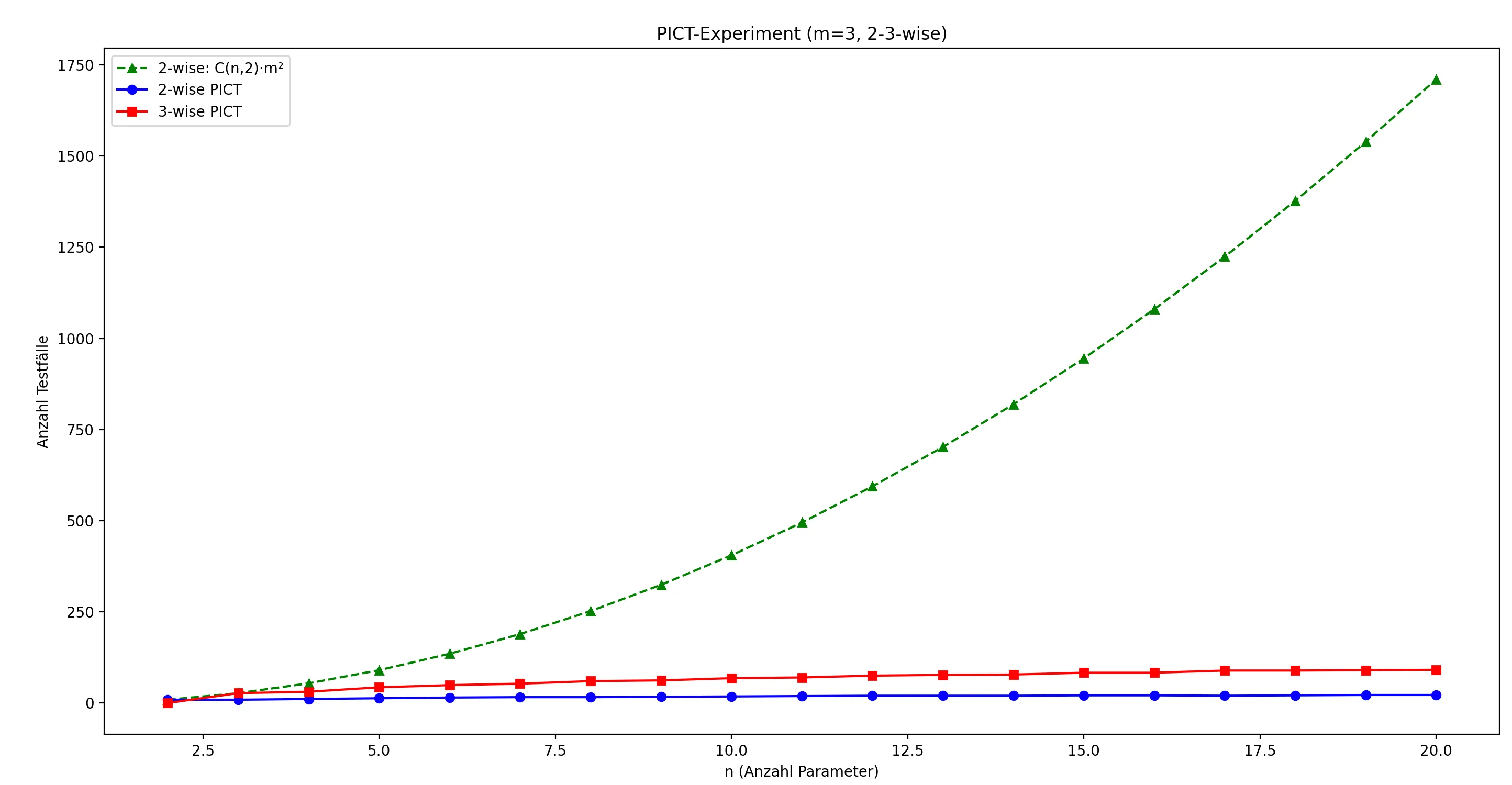
3-wise und Sub-Models
Wenn bekannt ist, dass die Parameterabhängigkeiten im Wesentlichen von mehr als zwei Parametern abhängen, kann das Verfahren entsprechend erweitert werden — mit dem Preis steigender Testfallzahlen. Anstatt hierbei alles auf 3-wise umzustellen, kann man über Sub-Models das 3-wise-Verhalten für einzelne Parametergruppen erzwingen:
# PICT-Beispiel: Versicherungsprodukt mit 7 Parametern
# Standard: paarweise Kombinationen über alle Parameter
# Aufruf z. B.: pict versicherung.txt /o:2
Laufzeit: 1 Jahr, 3 Jahre, 5 Jahre
Wohnfläche: 30 qm, 50 qm, 100 qm, 200 qm
Schmuck: 0 EUR, 100 EUR, 1000 EUR
Bonusrabatt: ja, nein
Zahlweise: monatlich, vierteljährlich, jährlich
Selbstbeteiligung: 0 EUR, 150 EUR, 300 EUR
Tarifvariante: Basis, Komfort, Premium
# Für die beitragsrelevanten Kernparameter wird zusätzlich 3-wise Coverage erzwungen.
{ Laufzeit, Wohnfläche, Schmuck, Selbstbeteiligung } @ 3Damit werden weiterhin alle Parameter grundsätzlich paarweise kombiniert. Für die definierte Gruppe aus Laufzeit, Wohnfläche, Schmuck und Selbstbeteiligung wird zusätzlich sichergestellt, dass alle 3er-Kombinationen innerhalb dieser Gruppe abgedeckt sind. Das ist besonders hilfreich, wenn fachlich bekannt ist, dass bestimmte Parameter gemeinsam auf die Prämie wirken, man aber nicht den gesamten Testraum auf 3-wise anheben möchte.
Negative Tests mit ungültigen Werten
PICT eignet sich nicht nur für gültige Kombinationen, sondern kann auch bei negativen Tests helfen. Damit sind Testfälle
gemeint, bei denen bewusst ungültige oder fachlich fehlerhafte Werte verwendet werden, um die Validierung des Systems zu
prüfen. Bei einem Versicherungsprodukt könnte das zum Beispiel eine negative Wohnfläche, eine Laufzeit von 0 Jahren oder
ein nicht erlaubter Schmuckwert sein.
Solche Werte können in PICT mit einer Tilde ~ gekennzeichnet werden:
Laufzeit: 1 Jahr, 3 Jahre, 5 Jahre, ~0 Jahre
Wohnfläche: 30 qm, 50 qm, 100 qm, 200 qm, ~-10 qm
Schmuck: 0 EUR, 100 EUR, 1000 EUR, ~-500 EURDer Vorteil dieser Kennzeichnung ist, dass PICT ungültige Werte kontrolliert behandelt. In der Regel wird pro Testfall nur ein negativer Wert verwendet. Das ist wichtig, weil ein Testfall mit mehreren ungültigen Eingaben oft schwer auszuwerten ist: Wenn gleichzeitig die Laufzeit, die Wohnfläche und der Schmuckwert falsch sind, ist nicht mehr eindeutig erkennbar, welche Validierung genau fehlgeschlagen ist. Negative Tests sollten deshalb bewusst sparsam eingesetzt werden. Sie ersetzen keine vollständige Validierungsstrategie, können aber sehr gut helfen, typische Fehleingaben systematisch in die generierten Testfälle aufzunehmen.
Gewichtung von Werten
Nicht alle Werte sind in der Praxis gleich wichtig. Manche Tarifvarianten werden besonders häufig verkauft, bestimmte Laufzeiten kommen öfter vor, und einzelne Kombinationen sind geschäftlich relevanter als andere. PICT ermöglicht es, solche Werte zu gewichten. Eine Gewichtung wird direkt hinter dem Wert angegeben:
Tarifvariante: Basis, Komfort, Premium (3)
Zahlweise: monatlich (2), vierteljährlich, jährlichIn diesem Beispiel wird Premium stärker bevorzugt als Basis oder Komfort. Ebenso wird die monatliche Zahlweise
häufiger berücksichtigt als die anderen Zahlweisen. Das bedeutet allerdings nicht, dass PICT daraus eine exakte
statistische Verteilung erzeugt. Die Gewichtung beeinflusst die Auswahl der Werte, aber das eigentliche Ziel bleibt
weiterhin die kombinatorische Abdeckung.
Gewichtung ist besonders dann sinnvoll, wenn bestimmte Werte im Test stärker sichtbar sein sollen, ohne dass man dafür
eigene Sondertestfälle schreiben möchte. Sie kann helfen, realistischere Testdaten zu erzeugen, etwa wenn ein Produkt in
der Praxis überwiegend mit bestimmten Optionen abgeschlossen wird. Gleichzeitig sollte man Gewichtung nicht mit
fachlicher Priorisierung verwechseln: Kritische Kombinationen sollten weiterhin explizit modelliert werden, zum Beispiel
über Sub-Models mit höherer Teststärke oder über zusätzliche manuelle Testfälle.
Ausschluss ungültiger Kombinationen
Ein Testmodell enthält oft Kombinationen, die theoretisch möglich wären, fachlich aber keinen Sinn ergeben. Solche Kombinationen sollten nicht als Testfälle erzeugt werden, weil sie das Ergebnis verfälschen und unnötigen Aufwand verursachen. PICT erlaubt deshalb den Ausschluss ungültiger Kombinationen über Constraints. Ein Beispiel: Ein hoher Schmuckwert ist möglicherweise nur in der Premium-Variante erlaubt.
IF [Schmuck] = "1000 EUR" THEN [Tarifvariante] = "Premium";Oder: Ein Bonusrabatt soll erst ab einer längeren Laufzeit möglich sein.
IF [Bonusrabatt] = "ja" THEN [Laufzeit] <> "1 Jahr";Solche Regeln sorgen dafür, dass PICT keine fachlich unzulässigen Testfälle erzeugt. Das ist besonders wichtig, wenn Testfälle später automatisiert ausgeführt oder an Fachbereiche zur Abnahme gegeben werden. Ein Testfall, der in der Realität gar nicht vorkommen darf, ist sonst schwer zu bewerten: Scheitert er wegen eines Fehlers im System oder weil der Testfall selbst ungültig ist? Wichtig ist aber die Unterscheidung zwischen „ungültig“ und „ungewöhnlich“. Eine kleine Wohnfläche mit einem Premiumtarif mag selten sein, kann aber fachlich durchaus erlaubt sein. Eine solche Kombination sollte nicht ausgeschlossen werden. Constraints sollten nur dort verwendet werden, wo eine Kombination tatsächlich fachlich verboten ist. Ein vollständiger Ausschnitt aus einer PICT-Datei könnte dann so aussehen:
Laufzeit: 1 Jahr, 3 Jahre, 5 Jahre
Wohnfläche: 30 qm, 50 qm, 100 qm, 200 qm
Schmuck: 0 EUR, 100 EUR, 1000 EUR
Bonusrabatt: ja, nein
Zahlweise: monatlich, vierteljährlich, jährlich
Selbstbeteiligung: 0 EUR, 150 EUR, 300 EUR
Tarifvariante: Basis, Komfort, Premium
IF [Schmuck] = "1000 EUR" THEN [Tarifvariante] = "Premium";
IF [Bonusrabatt] = "ja" THEN [Laufzeit] <> "1 Jahr";
IF [Tarifvariante] = "Basis" THEN [Selbstbeteiligung] <> "0 EUR";Durch solche Ausschlüsse wird das Modell fachlich genauer. PICT erzeugt dann nicht einfach beliebige Kombinationen, sondern Kombinationen, die innerhalb der definierten Geschäftsregeln gültig sind.
Typischer Ablauf in einem Testprojekt
In einem konkreten Testprojekt beginnt die Arbeit nicht mit PICT selbst, sondern mit der fachlichen Analyse des Tarifrechners. Zunächst müssen die relevanten Eingabeparameter bestimmt werden. Danach werden für jeden Parameter sinnvolle Werteklassen gebildet: Grenzwerte, typische Standardwerte, fachliche Sonderfälle und Werte unmittelbar vor oder nach einem Sprung in der Berechnungslogik.
Im nächsten Schritt werden fachliche Einschränkungen ergänzt. Nicht jede theoretisch mögliche Kombination darf auch im Testmodell vorkommen. Ungültige Kombinationen werden daher über Constraints ausgeschlossen. Für besonders kritische Parametergruppen kann zusätzlich eine höhere Kombinationsstärke definiert werden.
Erst danach werden mit PICT die eigentlichen Testdaten erzeugt. Diese Testdaten können anschließend gegen den Referenzrechner, zum Beispiel einen Excel-Rechner, ausgeführt werden. Die dort berechneten Sollwerte werden dann mit den Ergebnissen des Zielsystems verglichen. Auf diese Weise entsteht ein nachvollziehbarer Soll-Ist-Vergleich zwischen fachlicher Referenz und technischer Implementierung.
Grenzen des Verfahrens
PICT reduziert die Anzahl der Testfälle, aber nicht die Verantwortung für ein gutes Testmodell. Die Qualität der erzeugten Testfälle hängt wesentlich davon ab, ob die richtigen Parameter ausgewählt, passende Werteklassen gebildet und fachliche Abhängigkeiten korrekt modelliert wurden.
Das Verfahren ersetzt außerdem keine Grenzwertanalyse, keine fachlichen End-to-End-Szenarien und keine gezielten Regressionstests für bereits bekannte Fehler. Gerade bei Tarifrechnern bleiben zusätzliche Tests an fachlich relevanten Schwellenwerten wichtig, weil dort die größten Sprünge in der Berechnung auftreten können.
PICT ist deshalb am stärksten, wenn es als Baustein einer umfassenden Teststrategie eingesetzt wird: Es sorgt für eine systematische kombinatorische Abdeckung, während fachliche Analyse, Grenzwerttests und Regressionstests die inhaltliche Tiefe ergänzen.
Fazit
PICT ist kein Ersatz für fachliches Testdesign, aber ein sehr nützliches Werkzeug, um aus vielen Eingabeparametern eine überschaubare und dennoch systematische Menge von Testfällen zu erzeugen.
Gerade bei Tarifrechnern, deren Verhalten durch Lookup-Tabellen, Bedingungen und Sonderregeln geprägt ist, hilft das Verfahren dabei, relevante Parameterkombinationen nicht nur zufällig, sondern nachvollziehbar abzudecken.
Wichtig ist dabei, dass das PICT-Modell sorgfältig erstellt wird. Die Auswahl der Parameter, die Bildung sinnvoller Werteklassen, der Ausschluss fachlich ungültiger Kombinationen und die gezielte Erhöhung der Teststärke für kritische Parametergruppen entscheiden darüber, wie aussagekräftig die generierten Testfälle am Ende sind.
In einem Folgeartikel zeige ich an einem konkreten Beispiel, wie PICT in der Praxis zusammen mit einem Excel-Rechner eingesetzt werden kann: von der Modellierung der Eingabeparameter über die Generierung der Testdaten bis zum Vergleich der berechneten Ergebnisse mit dem Zielsystem.